NumPy vs Pandas Performance Benchmark
I kept hearing that NumPy is faster than Pandas — and in a lot of cases that's true. But I wanted to know by how much, and whether it's actually a fair universal claim. Turns out it isn't. So I built this project to get real numbers. I benchmarked seven operations across three dataset sizes using time.perf_counter() with 5 runs averaged per measurement. All data is generated synthetically with a fixed seed so the results are fully reproducible. Everything is explored in a Jupyter notebook with four chart types, and the raw numbers are exported to results.json.
Overview
Problem
I'd been told that NumPy is faster overall, but that felt too broad to be useful. Faster at what, exactly? And by how much? I wanted to know whether the advice held across different operations and dataset sizes, or whether it was really just true in specific situations that people had generalised a bit too confidently.
Solution
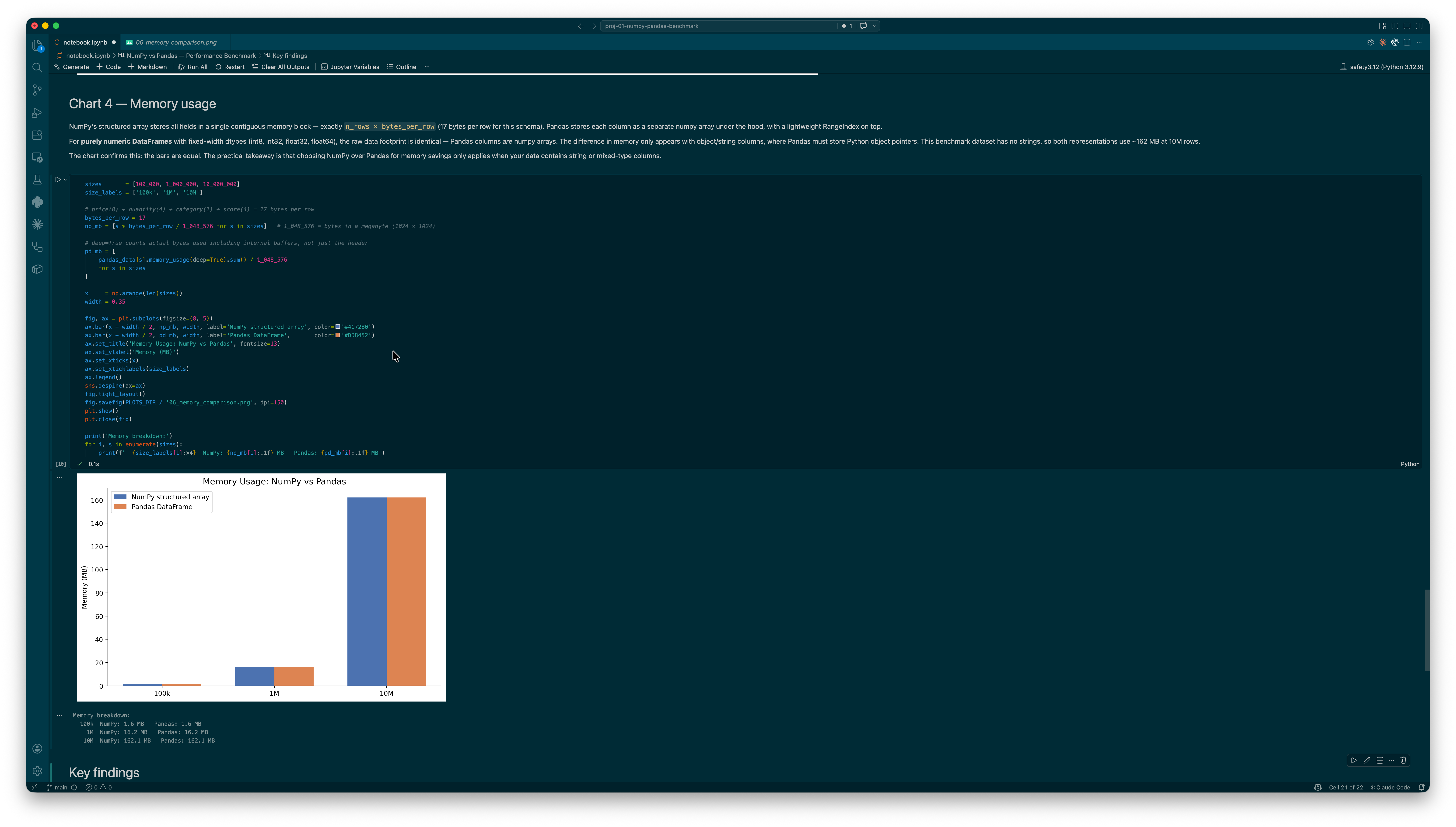
I generated a synthetic dataset with four columns — price, quantity, category, score — and timed seven operations for both libraries at 100k, 1M, and 10M rows. NumPy uses a structured array with named fields; Pandas uses a DataFrame built from the same seed so the values are identical. I used time.perf_counter() over 5 runs for each measurement, then visualised the results across four chart types to make the patterns easy to read.
Challenges
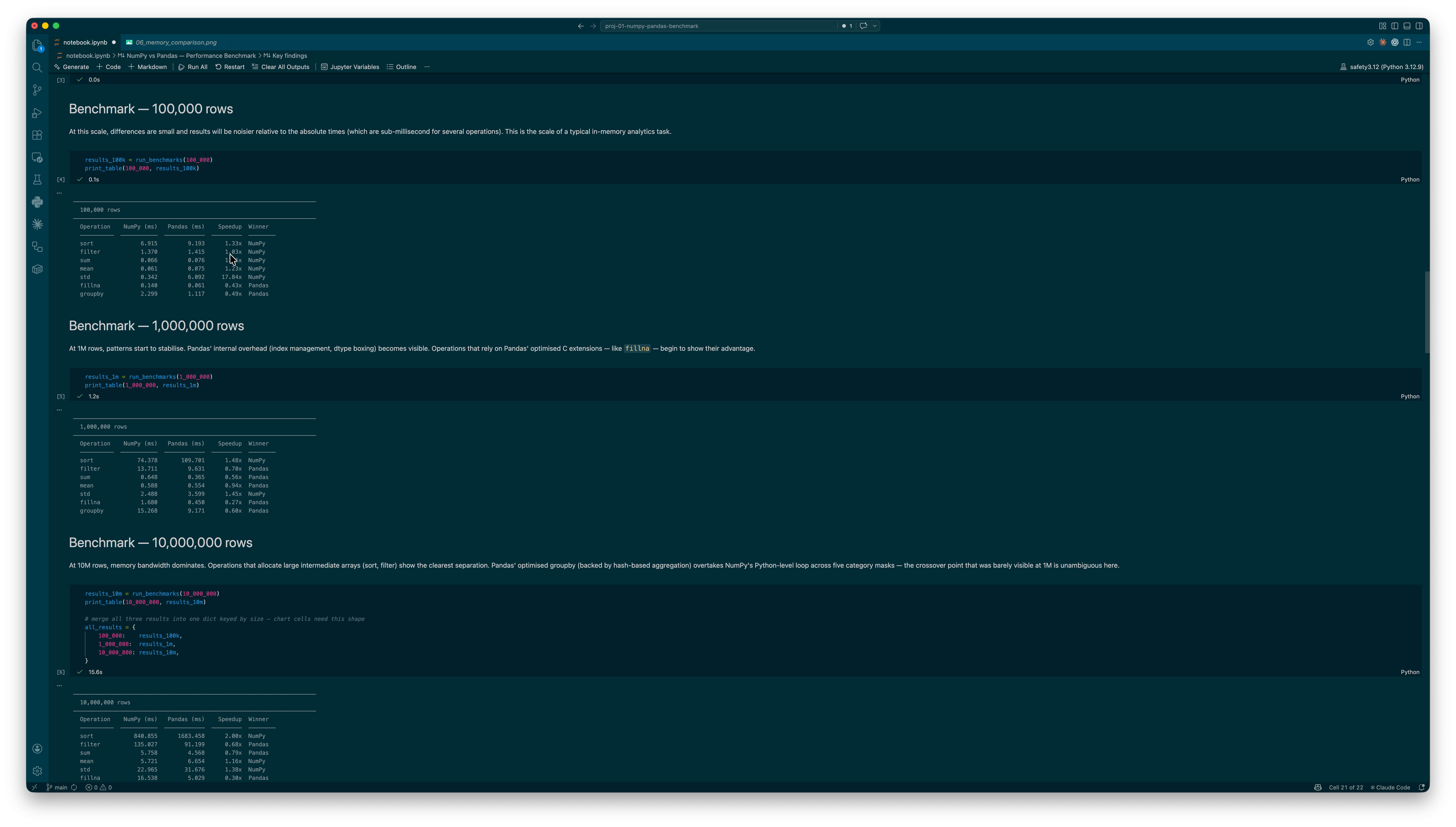
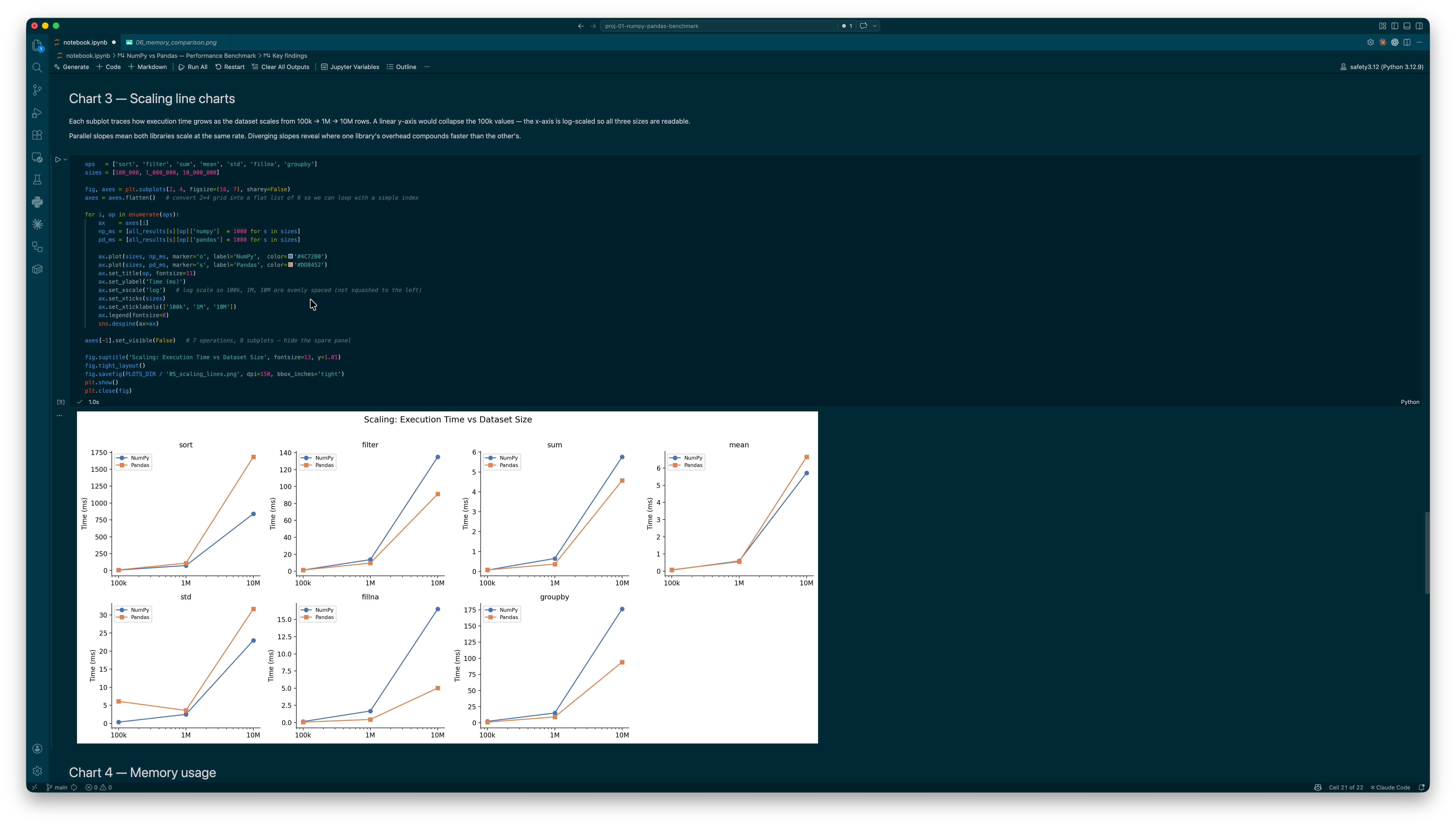
Getting the comparison to be genuinely fair took more thought than I expected. I had to make sure both libraries were working with the exact same data — same seed, same values, matching dtypes. The groupby benchmark was the most revealing: NumPy needs a Python-level loop over five boolean masks, while Pandas uses a hash-based engine under the hood. Watching NumPy win at 100k rows and then lose convincingly at 1M was the moment the project clicked for me — the crossover is real and it has a clear reason.
Results / Metrics
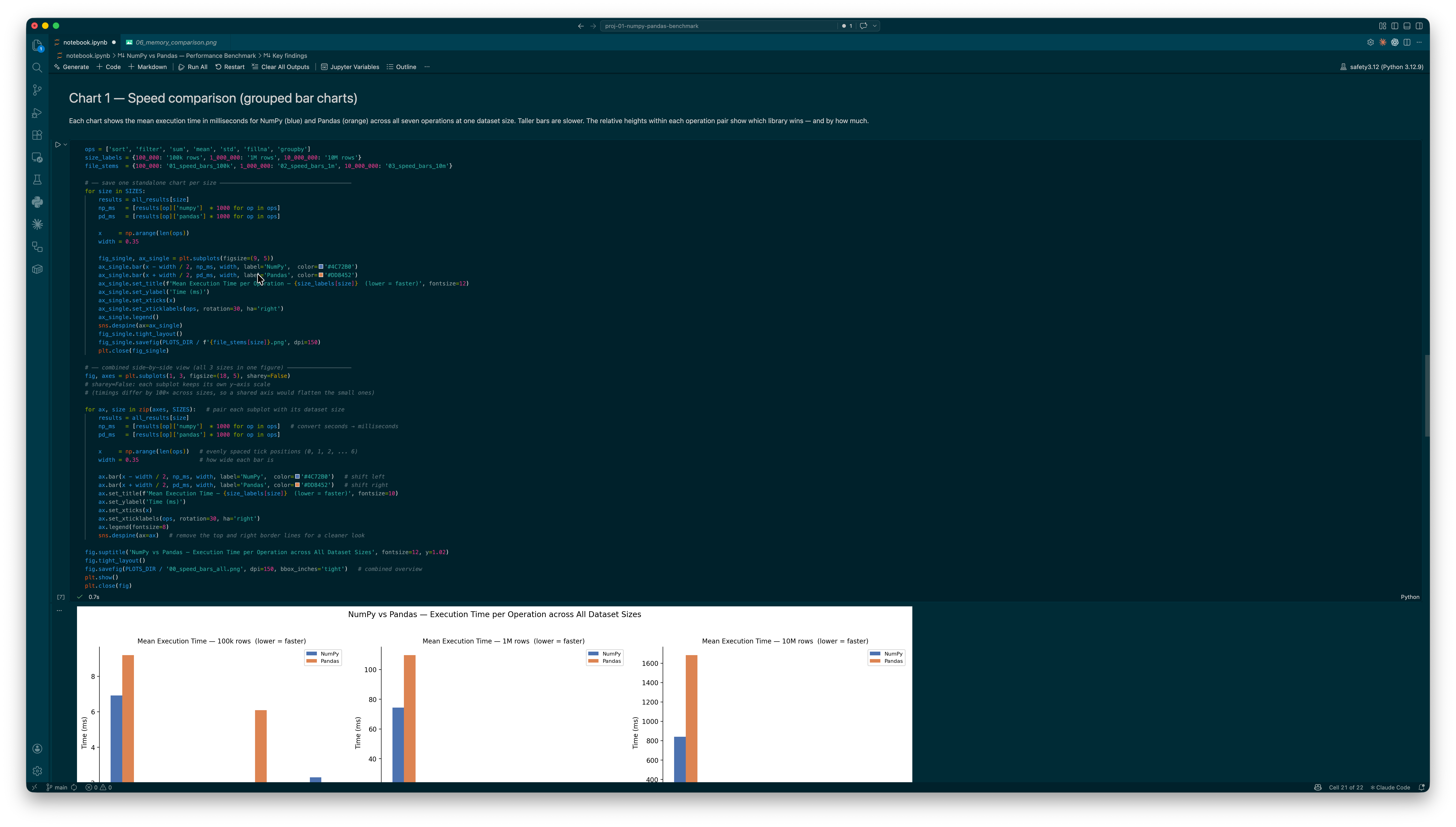
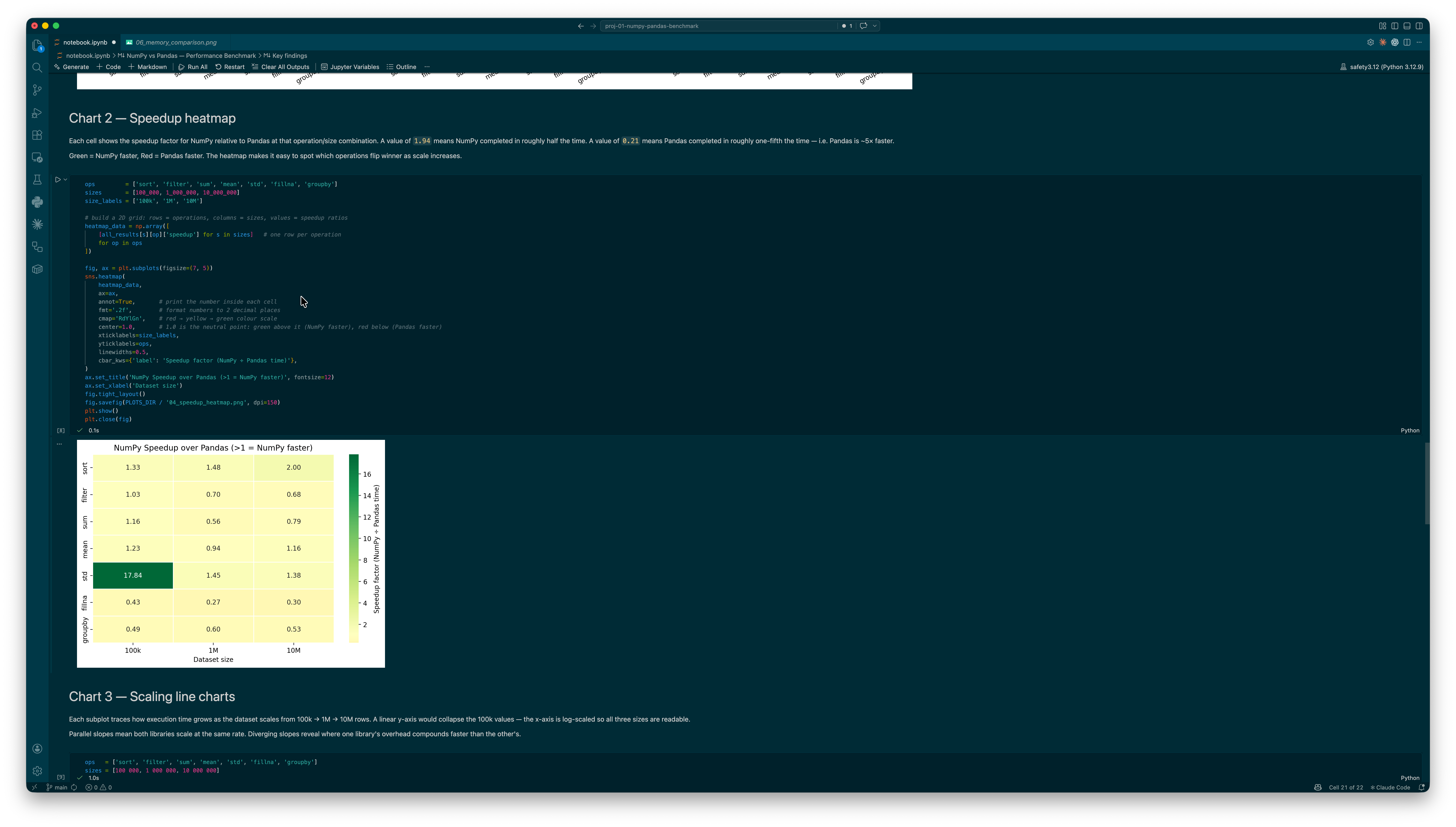
The "NumPy is faster" claim holds for some things and completely falls apart for others. NumPy is 1.5–1.9× faster at sorting at every scale I tested. But Pandas fillna beats the NumPy np.where equivalent by 3.3× at 10M rows. Pandas groupby goes from slower at 100k to 1.44× faster at 1M and beyond. Boolean filtering consistently favours Pandas by ~1.47×. The honest answer is: it depends on the operation, and the scale matters more than most people realise.
Screenshots
Click to enlarge.
Click to enlarge.
Videos
No videos available yet.